
Cet article est la deuxième partie d’une série axée sur la conception de métamodèles (plus précisement les modèles Ecore). À la suite de la première partie centrée sur certaines règles de base, cette deuxième partie se concentre sur des aspects légèrement plus techniques : la performance et Java. Le disclaimer général s’applique toujours :
La plupart des vérifications indiquées ici sont très faciles à respecter si elles sont prises en compte dès le début, mais pourraient ne pas être aussi abordables plus tard. De plus, cette liste n’est pas exhaustive et n’est pas nécessairement la vérité unique et universelle. Votre expérience peut varier, mais alors parlez-moi-en !
Performance

La conception de votre modèle Ecore a des implications en termes de montée en charge et de performances, en particulier en termes de mémoire et d’E/S, mais pas seulement.
Si vous voulez tirer le meilleur parti des technologies de modélisation Eclipse en général, vous devriez vérifier les points suivants.
☑ Les instances qui seront présentes en grand nombre dans les modèles ont une sérialisation concise
Demandez-vous : combien d’instances de cette EClass aurai-je généralement dans un modèle ? Si la réponse est “beaucoup” (100 000 par exemple), vérifiez comment elles seront sérialisées et assurez-vous qu’il n’y a pas d’amélioration que vous pourriez apporter sur la quantité d’information nécessaire.
Cela est particulièrement vrai lorsque vous utilisez la sérialisation XMI qui n’est pas la plus efficace en termes d’espace et qui parfois doit ajouter des directives supplémentaires pour identifier clairement les types cibles d’une référence, par exemple.
Cela est également très vrai pour les datatypes personnalisés.
Si ce datatype est utilisé par un grand nombre d’instances, assurez-vous que votre logique de sérialisation, codée par les méthodes fromString() et toString(), est concise.
☑ Tout ce qui est sérialisé doit être sérialisé

Vous avez besoin de ce modèle, mais y a-t-il des parties qui n’ont pas besoin d’être sérialisées ? Pouvez-vous éliminer certaines parties de l’information ? Quelles informations sont réellement saisies par les utilisateurs par opposition aux informations qui sont inférées par l’outil ? Y a-t-il une partie de ces données qui a un cycle de vie plus court que “charger le fichier”/”sauvegarder le fichier” ? D’autres éléments y font-ils référence ?
Ces questions sont utiles pour identifier les sous-graphes complets du modèle qui n’ont pas besoin d’être sérialisés. Vous ne pourrez jamais être plus rapide qu’éviter de faire un travail inutile. Cela dit, si vous avez besoin de ces informations et que vous les recalculez chaque fois que vous utilisez le modèle, cela peut ne pas être rentable, ça se mesure!
☑ Les références dérivées sont rapides, simples ou externalisées
Avec Ecore, vous pouvez définir des références (et des attributs d’ailleurs) dont la valeur est dérivée, souvent en codant manuellement la logique Java. Les outils et les cadres de l’écosystème EMF sont susceptibles d’accéder à ces caractéristiques lors de la découverte réflexive de votre modèle et supposent généralement une complexité CPU proche d’un accès à un champ : assurez-vous que la logique Java qui les implémente est rapide et ne dépend pas d’un cadre externe. Si ce n’est pas le cas, il est préférable de l’exposer soit en tant qu’EOperation (elle ne sera pas invoquée de manière réflexive), soit en définissant une API Java dédiée.
☑ Il n’y a pas d’EClass qui pourrait être remplacée par un EDatatype
Toute EClass utilisée pour un nombre important d’instances doit être inspectée et une décision consciente doit être prise quant à savoir si elle est mieux modélisée en tant qu’EClass ou en tant qu’EDatatype. Même avec le Régime Ultra Mince EMF, un EObject vient avec un surcoût, tant en termes d’utilisation de la mémoire que, plus important encore, en termes de surcoût que le code du cadre peut induire (référenceurs croisés, enregistreurs de changements..).
Règle générale : si vous avez de nombreuses instances qui ne seront jamais référencées par une autre instance à part la contenant et que vous n’avez pas vraiment besoin des notifications de changement individuelles de chaque attribut de l’EObject, alors il est probablement préférable de le modéliser en tant qu’EDatatype. Lorsqu’une EClass n’a que des EAttributes, aucune EReference et n’est pas référencée par d’autres objets à part son conteneur, c’est également une indication claire que cela pourrait être un bon candidat pour être un EDatatype.
☑ Le modèle a une structure
Évitez les modèles plats avec des dizaines de milliers d’instances dans une seule valeur de référence pour deux raisons principales :
- Pour des raisons historiques, EMF vérifie l’unicité de chaque ajout, ce qui signifie qu’un appel à
.add()vérifiera chaque élément de la liste. (Il existe des moyens d’éviter explicitement ces vérifications en utilisantaddUnique()). - Afficher le contenu de la référence dans l’interface utilisateur peut entraîner la création de dizaines de milliers d’éléments SWT dans une liste ou un arbre. SWT n’est pas taillé (par défaut) pour cela et cela peut entraîner de longs blocages de l’interface utilisateur.
Sirius est capable de détecter ces situations et de regrouper visuellement ces références, mais vous ne pouvez pas compter sur cela pour chaque widget arborescent.
☑ Il est possible de charger une partie du modèle sans tout charger
Les références croisées modélisées avec EOpposites tendent à introduire des dépendances entre plusieurs fichiers de modèle ; transitivement, il devient rapidement impossible de charger un fichier du modèle sans tout charger.
Si vous visez la montée en charge et la performance, la capacité à se concentrer sur un sous-ensemble du modèle est un atout important. Vous devriez donc éviter les références EOpposites qui introduiraient des relations inter-fichiers.
☑ Les classes d’implémentation utilisent MinimalEObjectImpl
Assurez-vous que votre .genmodel est configuré pour utiliser MinimalEObjectImpl. C’est le paramètre par défaut si vous avez créé votre genmodel avec une version récente d’EMF. Plus d’informations à ce sujet sont disponibles sur le blog d’Ed.
___
Java
☑ L’héritage multiple n’est pas surutilisé

Ecore permet l’héritage multiple. Mais en fin de compte, votre modèle Ecore est transformé en code Java et Java permet uniquement la mise en œuvre de multiples interfaces.
Le générateur de code EMF masque cela pour vous et va finir par dupliquer du code pour s’assurer que tout fonctionne comme prévu. Quelques points à garder à l’esprit :
- l’ordre de l’héritage est important : la classe d’implémentation étendra la classe d’implémentation de la première EClass dans la liste des supertypes, les classes suivantes entraîneront une duplication de code.
- tout comme pour les conceptions orientées objet, avoir beaucoup d’héritage multiple indique un design qui ne sépare pas vraiment les préoccupations (ou pas les bonnes)
☑ Les DataTypes personnalisés sont utilisés à bon escient
EMF fournit des datatypes prêts à l’emploi pour les Strings, Integer, Float, Long et leurs équivalents primitifs comme EString, EInt …

Mais String est une préoccupation technique et il pourrait rendre la conception plus évidente de remplacer les usages de EString par votre propre EDataType s’il exprime un type spécifique au domaine, même si vous le conservez mappé sur java.lang.String.
Cela rend le modèle Ecore plus explicite et ouvre la voie à un comportement qui peut être spécifique à ce type particulier.
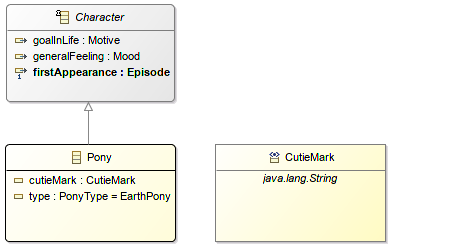
Si votre datatype personnalisé n’est pas mappé à un type Java très standard, assurez-vous alors que votre implémentation respecte le contrat equals/hashcode sinon des outils comme EMF Compare n’auront aucun moyen de comparer ces valeurs individuelles.
☑ Les dossiers de génération du .genmodel sont spécifiés ou bien nuls
Une simple action de clic droit, Generate All sur le genmodel devrait donner le résultat que vous souhaitez. Ne comptez pas sur le fait que les gens savent à l’avance que vous devriez uniquement générer les plugins model et edit par exemple.
Ne les faites pas réfléchir à ce genre de choses.
Vous pouvez le faire en rendant vides les propriétés [...] Directory correspondantes dans l’instance genpackage.
L’éditeur adaptera alors son menu contextuel et Generate all ne lancera pas la génération des tests.
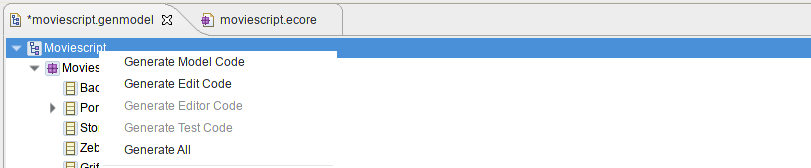
De plus, il est généralement préférable d’utiliser src-gen au lieu de src comme dossier final, profitez-en pour mettre à jour cela en même temps.

☑ La propriété basePackage .genmodel est spécifié
Définissez la propriété base package dans le fichier .genmodel car elle détermine votre espace de noms Java. Vous ne devriez jamais introduire de EPackages vides pour obtenir le résultat de l’espace de noms Java que vous souhaitez, mais vous devriez plutôt utiliser la propriété paquet de base.

C’est tout pour le moment. Si vous commencez avec cette liste de contrôle, vous aurez couvert les bases.
Mon objectif avec EcoreTools est de vous aider à prendre en compte ces aspects, c’est pourquoi de nombreuses règles sont illustrées par des fonctionnalités spécifiques de cet éditeur de diagrammes. Vous trouverez cet outil dans le Package de modélisation Eclipse et le site web EcoreTools explique comment commencer à l’utiliser.
Essayez-le, tout est Open-Source et fait partie d’Eclipse !
Crédits : merci à Pierre-Charles et Mélanie pour la relecture, Jan pour avoir apporté un nouvel élément et Roxanne pour certains des poneys.