
Ok, you’re stuck at home, you are one of the numerous budget shortcuts victims? You did not have the chance to come at EclipseCon? Here is some kind of transcript of the talk I just gave:

This talk tackles team-working with models. Once you use models in your development process, they matter as much as the source code. Don’t you want to be able to diff, merge or even patch your models just like with text files?
The good news is that, unlike text files, models have a semantic structure defined thanks to their Ecore model; as such we’re able to semantically compare the models. Comparing the serialization (XMI or other) is often meaningless.
By the way I’m the project lead of EMF Compare. The project was contributed to Eclipse in early 2007 — at that time many EMF adopters realized that this piece was missing in the Modeling ecosystem and this lack was often a blocker!

So here we are, three years later. EMF Compare — in the EMF Technology project at first — graduated and is now part of the EMF project itself!
Just like Transaction, Validation or CDO, Compare is one of the many pieces you can reuse as a framework, or just as a tool. Its focus is quite narrow: comparing, merging and patching any kind of EMF model, be it a UML model or a domain-specific one.
As we graduated we’ve been focusing on keeping stable API you can rely on. We really think that EMF popularity is highly due to the fact that depending on it is easy as it is completely forward compatible. Working nicely as a pure Java jar library is another key asset of EMF; we tried to stick to that for the Compare project: our framework can be used as a Java jar, not depending on Equinox or any extension point.

We could phrase the Eclipse IDE spirit as: be extensible, be customizable, be integrated. We are sticking to this motto too — you can extend or customize any part of the comparison process.
The compare and merge features are completely integrated with the Eclipse Team API. When you launch a comparison from the workspace or from a history, if the file is in fact a model, EMF Compare will be opened and will show you the differences, allowing you to merge, or switch back to the serialization diff.
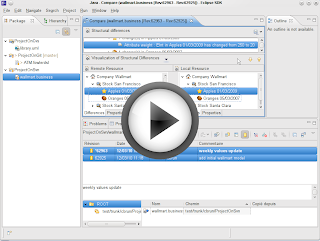
Let’s have a look at the tool through a demo. This demo goes higher and higher in coolness; as such it’s starting by comparing an old-fashioned UML model on a dying CVS Repository.
A bit more cool: comparing a domain-specific model on an SVN repository.
Total coolness: comparing an XText DSL semantically, merging it, on top of a GIT repository!

That’s just the tip of the iceberg; EMF Compare has a few more features and is especially useful in a lot of contexts. Rather than listing all these details I’ll focus now on the inside, revealing which kind of magic makes this clock ticking.
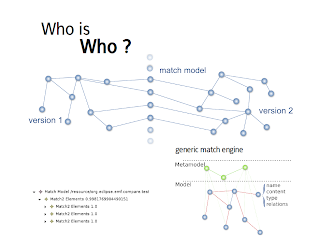
As I said at the beginning, the good news comparing models is that we’ve got semantic information — we’re not comparing plain text. There is a drawback though: models are graphs and, as such, being able to match similar graphs is a complex and tricky problem.
The first thing we have to do for a comparison is to match the elements from both versions of the model.
If you’ve got IDs that part is trivial: EMF Compare will use your IDs (either business ones or technical ones). On the other hand, if you don’t, we are providing what we call the “generic match engine”. This engine uses a few statistical metrics to match the elements.
For a given element this engine will extract its type information, the content values, its relations with other elements and its name if we can detect one. Each piece of this extraction will be compared with other elements to compute a similarity coefficient; from this we can try to get closer and closer to the perfect match.
Once this engine has done its job, it provides a Match Model grouping all this information and weaving the other models.
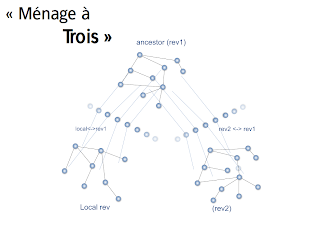
It gets more complicated (and then more interesting) when using source-control management systems. Then you have to match three versions of a model: yours, the remote one, and the common ancestor between those versions.
To do so we build two match models, between your local version and the common ancestor, then between the remote version and the common ancestor, and we combine those two match models into one, weaving the three models altogether.
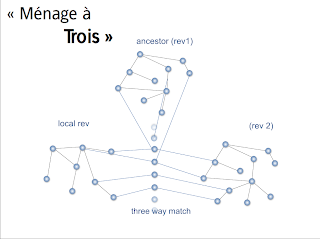
At this stage it should be obvious that the faster the match engine is, the faster you’ll get a result.
To be honest the generic match engine is not so fast; having little clue about the models it’s matching, it spends a lot of time browsing the structure, trying to match things which probably have no possibilities of being the same.
Being aware of that we eased the definition of your own match engine specific to your Ecore model. In doing so, no doubt you’ll get better results and way faster.
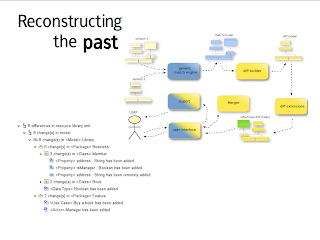
Let’s take a step back. What are we trying to do?
We are trying to change two versions of a graph into a set of events; in reality we are trying to re-construct “a posteriori” the history of the graph: what changes have been made to transform the original one to the new one.
Match computation is done by the Match Engine; the diff by the Diff Engine. This processor has to provide a Diff Model from a Match Model.