
This article is the second part of a series focusing on metamodel design (more especially Ecore models). Following the first part focused on some ground rules this second part is focused on slightly more technical aspects: scalability and Java. The general disclaimer still applies:
Most of the checks stated here are very easy to comply with when considered from the start but might not be that cheap later on. Furthermore this list is not exhaustive and not necessary the unique and unviversal truth. Your mileage may vary but then tell me about it!
Scalability

The design of your Ecore model has scalability and performances implications, most especially memory and I/O wise but not only.
If you want to get the most of Eclipse Modeling technologies in general you should check the following items.
☑ Instances which will be present a lot in the models have a concise serialization
Ask yourself: how many instances of this EClass will I usually have in a model? If the answer is “quite a lot”(100K for instance) then check how they will be serialized and make sure there is not an improvement you could bring here.
This is particularly true when you use the XMI serialization which is not the most space efficient one and might need to add extra informations to clearly identify types for instance.
This is also very true for custom datatypes.
If this datatype is being used by a lot of instances then make sure your serialization logic which is coded through fromString() and toString() methods is concise.
☑ Everything which is serialized needs to be serialized

You need this model, but are there parts which have no need to be serialized? Can you strip out parts of the information? What information is actually captured by the users in opposition to the information which is infered by the tool? Is there any part of this data which has a shorter lifecycle than “load the file”/”save the file”? Are other elements referencing it ?
Those questions are useful to identify complete sub-graphs of the model which have no need to be serialized. You can’t get faster than not doing any work. That being said, if you need this information and recompute it each time you use the model, then it may not pay off.
☑ Derived features are fast, straightforward, or externalized
Using Ecore you can define derived features, often by hand-coding the Java logic. Tools and frameworks in the EMF eco-system are likely to access those features when reflectively discovering your model and generaly assume a CPU commplexity which is close to a field access: make sure the Java logic implementing it is fast and does not depend on some external framework being there. If it’s not the case it is better to expose it either as an EOperation (it will not be reflectively invoked), or defining a dedicated Java API.
☑ There is no EClass which could be replaced by an EDatatype
Any EClass used for an important number of instances should be inspected and a conscious decision should be made about whether it is best modeled as an EClass or as an EDatatype. Even with the EMF Ultra Slim Diet an EObject comes with an overhead, both in term of memory usage but even more importantly in the overhead framework code might induce (cross-referencers, change recorders..).
Rule of thumb: if you have many instances which will be never referenced by other instance beside the containing one and you don’t really need the individual change notifications of each attribute of the EObject, then it’s probably best to model it as an EDatatype. When an EClass only have EAttributes, no EReference and is not referenced by other objects besides its container it is also a clear indication that this might be a good candidate for being an EDatatype.
☑ The model has some structure
There are two main reasons to stay away from flat models with tens of thousands of instances in a single reference value:
- for legacy reasons, EMF will check the uniqueness of any addition and as such in the Java implementation, a call to
.add()will check for every item in the list. (there are way to explicitely avoid those checks by usingaddUnique()) - displaying the reference content in the user interface will likely lead to the creation of tens of thousands of SWT items in a list or in a tree. SWT is not good at that and that might lead to long freezes.
Sirius is kind enough to detect those situations and group such references, but you can’t count on that for every tree viewer.
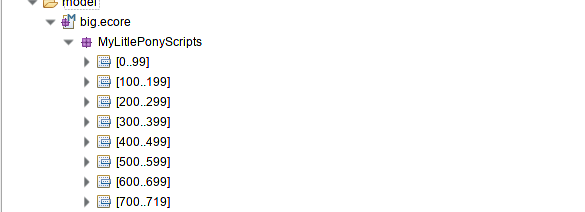
☑ It is possible to load part of the model without loading everything

Cross-references modeled with EOpposites tend to introduce dependencies among several model files; transitively it quickly become impossible to load a file from the model without loading everything.
If what you aim for is scalability and performance the capability to focus on a subset of the model is a strong asset, as such you should avoid EOpposites references which would introduce inter-files relationships.
☑ The implementation classes are using MinimalEObjectImpl
Make sure your .genmodel is configured to leverage MinimalEObjectImpl. This is the default if you created your genmodel with a recent version of EMF, more information about this is available on Ed’s blog
Java
☑ L’héritage multiple n’est pas surutilisé

Ecore permet l’héritage multiple. Mais en fin de compte, votre modèle Ecore est transformé en code Java et Java permet uniquement la mise en œuvre de multiples interfaces.
Le générateur de code EMF masque cela pour vous et pourrait finir par dupliquer du code pour s’assurer que tout fonctionne comme prévu. Quelques points à garder à l’esprit :
- l’ordre de l’héritage est important : la classe d’implémentation étendra la classe d’implémentation de la première EClass dans la liste des supertypes, les classes suivantes entraîneront une duplication de code.
- tout comme pour les conceptions orientées objet, avoir beaucoup d’héritage multiple indique un design qui ne sépare pas vraiment les préoccupations (ou pas les bonnes)
☑ Les DataTypes personnalisés sont utilisés dans chaque situation où cela a du sens
EMF fournit des datatypes prêts à l’emploi pour les Strings, Integer, Float, Long et leurs équivalents primitifs comme EString, EInt …

Mais String est une préoccupation technique et il pourrait rendre la conception plus évidente de remplacer les usages de EString par votre propre EDataType s’il exprime un type spécifique au domaine, même si vous le conservez mappé sur java.lang.String.
Cela rend le modèle Ecore plus explicite et ouvre la voie à un comportement qui peut être spécifique à ce type particulier.
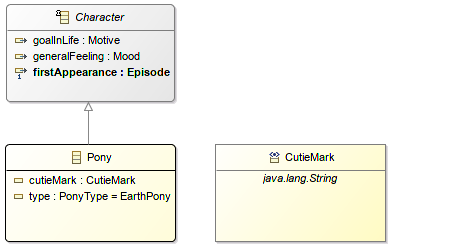
Si votre datatype personnalisé n’est pas mappé à un type Java très standard, assurez-vous alors que votre implémentation respecte le contrat equals/hashcode sinon des outils comme EMF Compare n’auront aucun moyen de comparer ces valeurs individuelles.
☑ Les dossiers de sortie du .genmodel sont spécifiés ou nuls
Une simple action de clic droit, Generate All sur le genmodel devrait donner le résultat que vous souhaitez. Ne comptez pas sur le fait que les gens savent à l’avance que vous devriez uniquement générer les plugins model et edit par exemple.
Ne les faites pas réfléchir à ce genre de choses.
Vous pouvez le faire en rendant vides les propriétés [...] Directory correspondantes dans l’instance genpackage.
L’éditeur adaptera alors son menu contextuel et Generate all ne lancera pas la génération des tests.
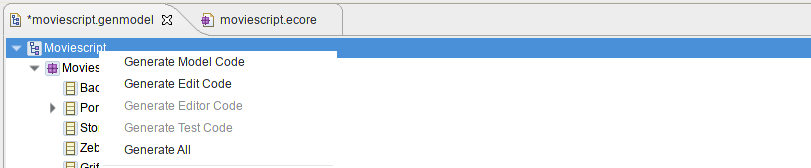
De plus, il est généralement préférable d’utiliser src-gen au lieu de src comme dossier final, profitez-en pour mettre à jour cela en même temps.

☑ Le paquet de base du .genmodel est spécifié
Définissez la propriété paquet de base dans le fichier .genmodel car elle détermine votre espace de noms Java. Vous ne devriez jamais introduire de EPackages vides pour obtenir le résultat de l’espace de noms Java que vous souhaitez, mais vous devriez plutôt utiliser la propriété paquet de base.

C’est tout pour le moment. Si vous commencez avec cette liste de contrôle, vous aurez couvert les bases.
Mon objectif avec EcoreTools est de vous aider à prendre en compte ces aspects, c’est pourquoi de nombreuses règles sont illustrées par des fonctionnalités spécifiques de cet éditeur de diagrammes. Vous trouverez cet outil dans le Package de modélisation Eclipse et le site web EcoreTools explique comment commencer à l’utiliser.
Essayez-le, tout est Open-Source et fait partie d’Eclipse !
Crédits : merci à Pierre-Charles et Mélanie pour la relecture, Jan pour avoir apporté un nouvel élément et Roxanne pour certains des poneys.